以
state.x77数据集为例
概念
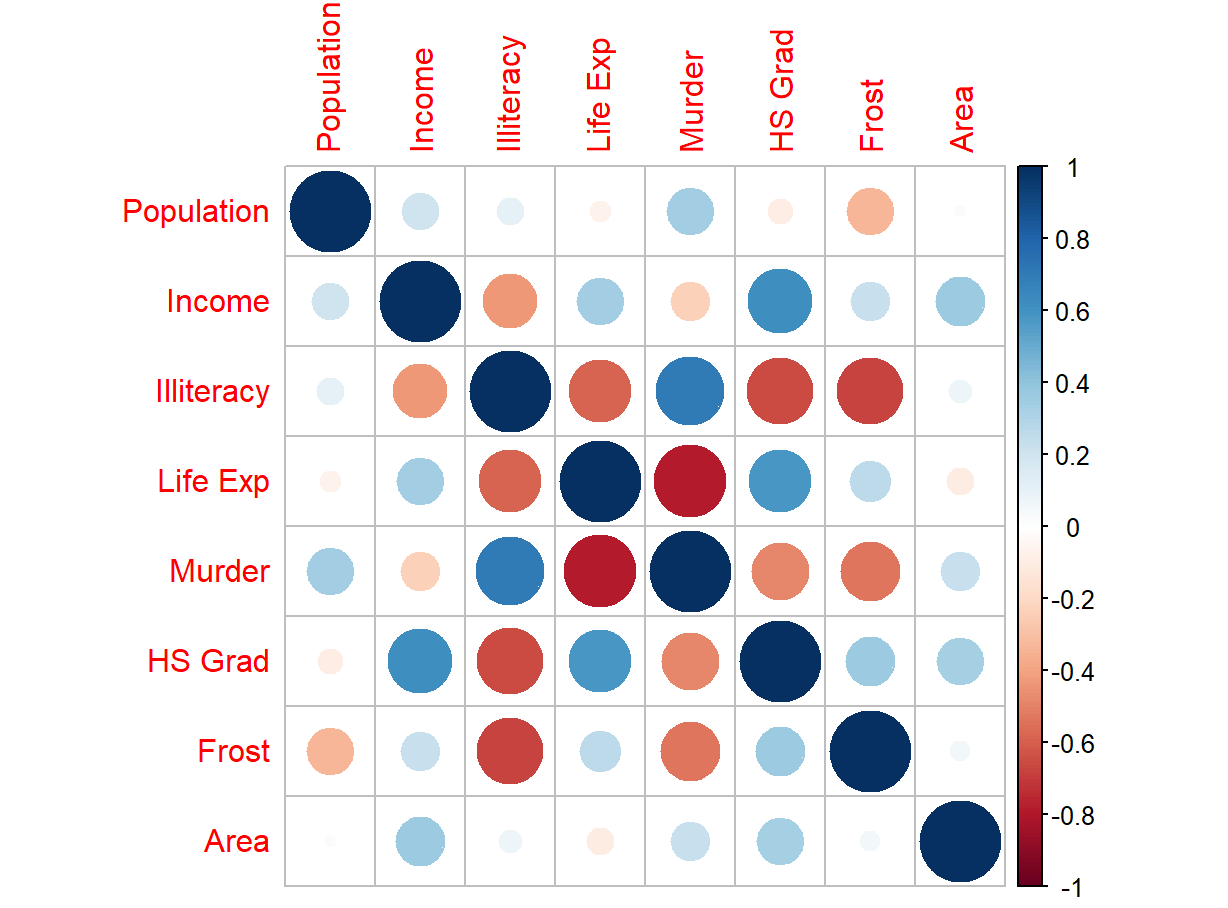
热图是相当常用的一类统计图,其原理就是将矩阵中每个位置的数值大小映射为颜色深浅,并排列在对应的位置上
由热图,可以对数据进行聚类
注意绘制热图的数据格式一定是矩阵
绘图包选择
一不使用自带的 heatmap 作图,常使用 pheatmap 等
标准化与中心化
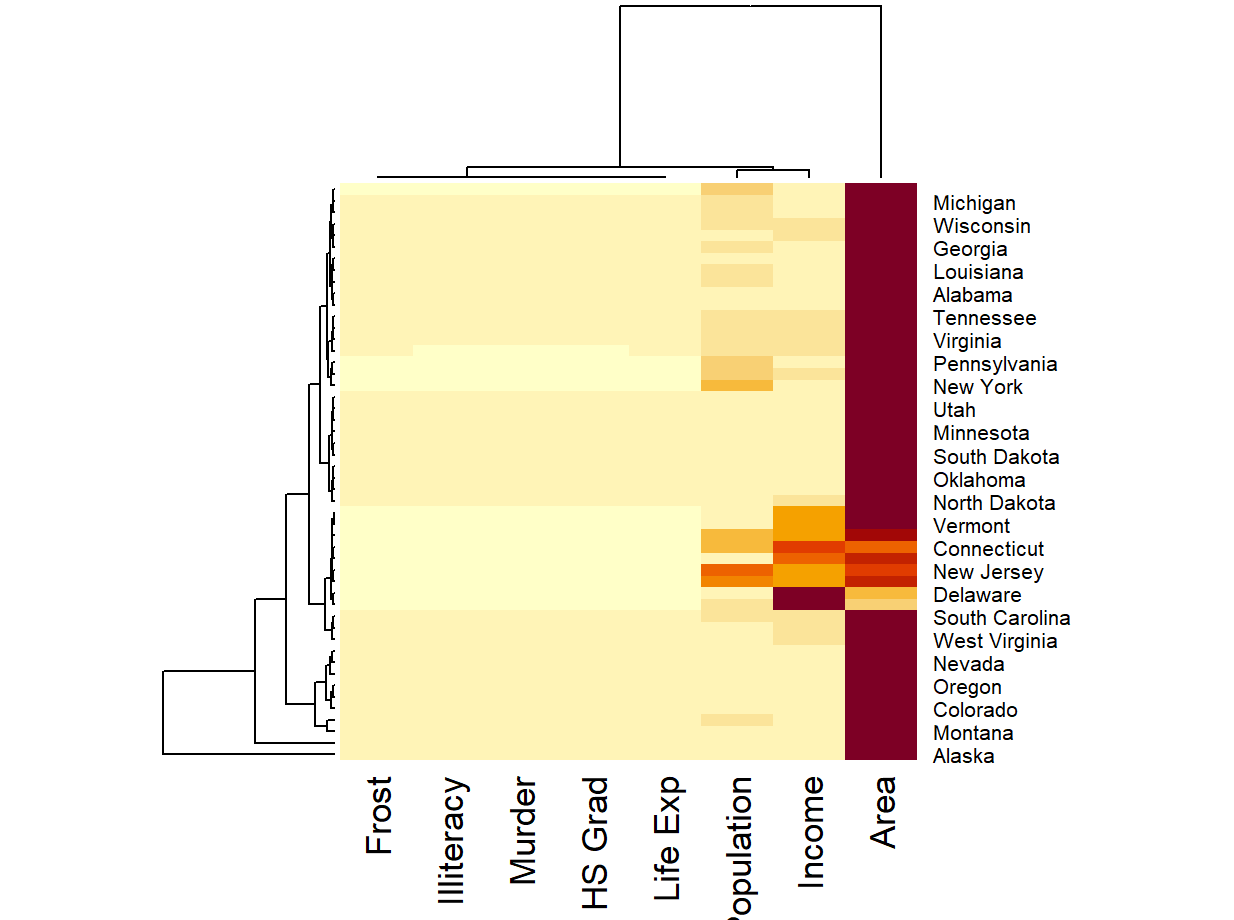
有时,由于数据单位等原因,不同数据间的差距可能很大,比如:州面积与文盲率。而在这往往导致其他数据间的差距被掩盖,比如:文盲率与谋杀率
在未标准化、中心化前,对数据集作热图如下,可见就”面积”一列最红,而其他数值差距很不明显。面积显然最大,这样的图没有意义
 使用
使用 scale() 函数可以对一个数值矩阵进行标准化和中心化,解决以上问题
heatmap(scale(state.x77)) scale() 处理后的图如下所示:
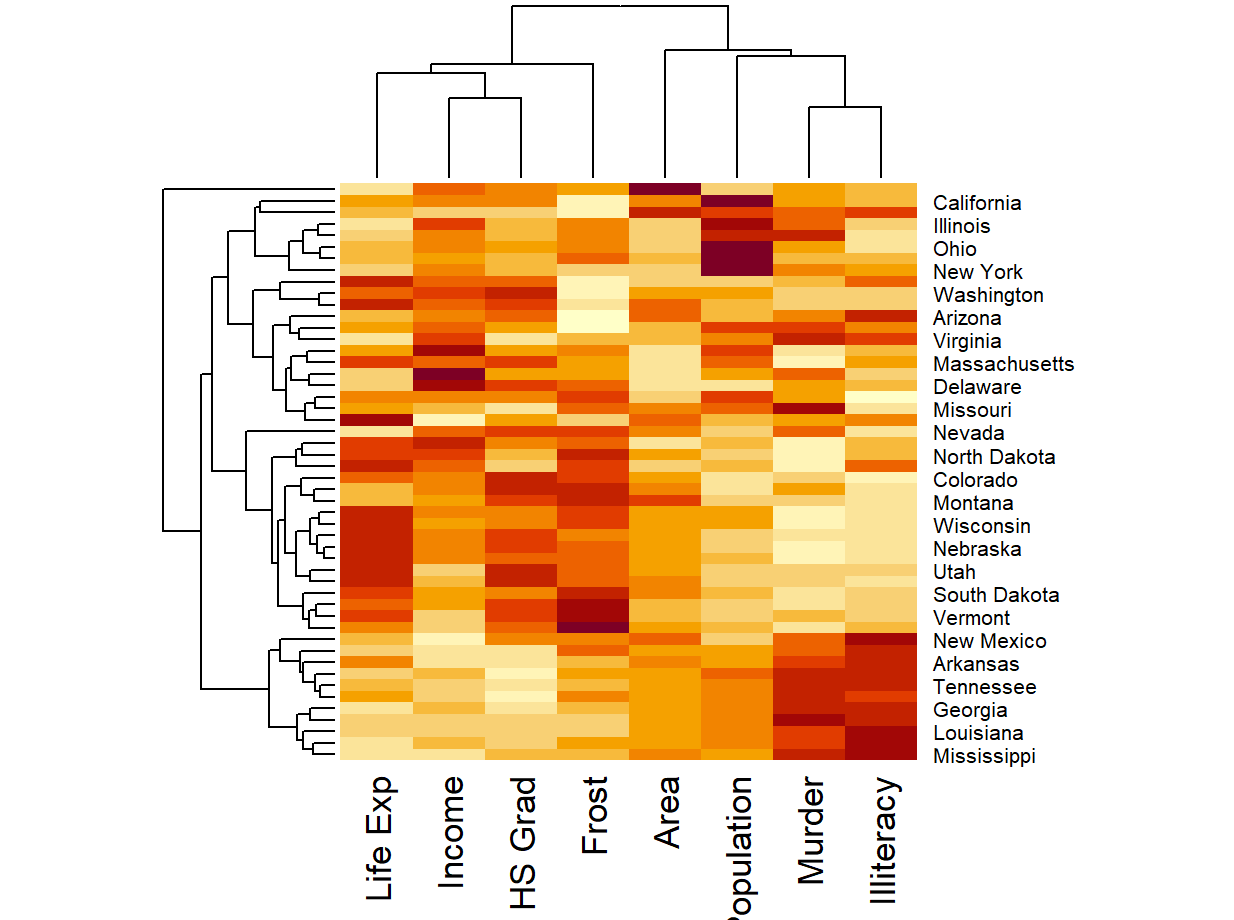 由此,差异便相当明显了。比如新墨西哥州的谋杀和文盲率就很高
由此,差异便相当明显了。比如新墨西哥州的谋杀和文盲率就很高
聚类分析
热图中每行每列的排列并不是随机的。在可视化数值大小的同时,R 进行了对数据的聚类,并将相似的数据排在了一起
注意到热图周边的树形图,它表示的就是行列间的相似性。节点的含义如下表
| 元素 | 含义 | |
|---|---|---|
| 叶子节点 | 代表单个数据点(一行或一列) | |
| 内部节点 | 代表两个或多个子簇的合并点,位置高度表示合并时的距离(不相似性) | |
| 分支长度 | 反映两个簇之间的差异程度,长度 ∝ 不相似性。 |
比如,由矩阵与相关性中的结果可得到如下相关性图,注意到文盲率和谋杀率相关性最高。在热图中,它们也被放置在了相邻的位置