缺失数据与缺失值
由于各种原因,数据集中不可避免的将出现缺失数据,在统计学中有专门处理缺失值的方法
缺失数据在 R 中一般为 NA
处理缺失值
以下介绍几种处理缺失值的方法
直接删掉
有时可以直接删掉缺失值,很简单。
值得注意的,最好按行进行删除,因为行代表观测(样本),数据缺失时只是样本应当删去,而不是变量,也就是列,应该被删去
删除所有含 NA 的行
na.omit(sleep)插值法
插值法(impute)就是用其他值计算得到的统计量(均值、分位数等)代替缺失值
总之,就是使用计算的方法填补缺失值,并尽可能使填补的值接近真实值
例如,使用 k 近邻插补法
sleep_imputed <- kNN(sleep)VIM 包
VIM 包是用于处理缺失数据集的工具包,介绍几个较为核心的功能
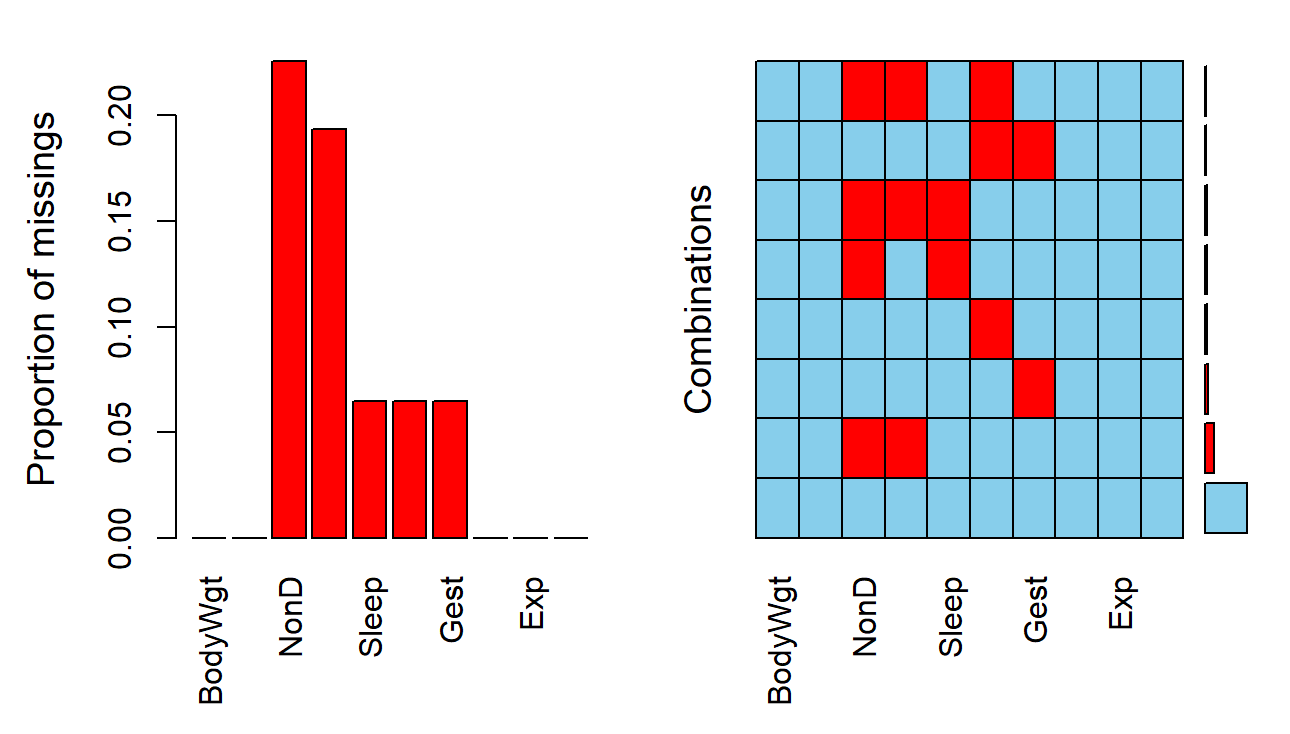
缺失值可视化
先对缺失值进行整合(aggregate)后可作图可视化缺失值
a <- aggr(sleep, plot = F) #输出文字统计
a <- aggr(sleep) #直接作图