简介
SNP 芯片(SNP array)是一种高通量的基因分型技术,可以快速低成本地鉴别 SNP 位点。
传统的 SNP 分型技术依赖 PCR 和 Sanger 测序,即先在 SNP 位点两侧设计引物,扩增 SNP 后进行 Sanger 测序直接读取位点序列,这种方法中,一个反应只能检测 1 个 SNP,效率低下。而 SNP 芯片利用碱基互补配对原则,通过芯片上的探针“捕捉”样品DNA片段,再读取“荧光信号”来判断基因型。
原理
以下原理以 Illumina 为例。
1. 芯片的结构
SNP 芯片虽然叫“芯片”,但其实和计算机的芯片基本没有关系,根据英文直译,这是一种集成在一张chip (芯片)上的 array (阵列)。
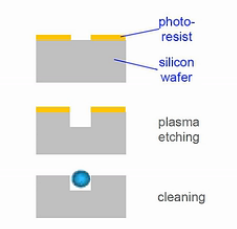
SNP 芯片外观上接近一张载玻片,具体组成结构如下:
- 经过光蚀刻的玻璃基片
- 固定在基片光蚀刻孔中的微珠(μm)
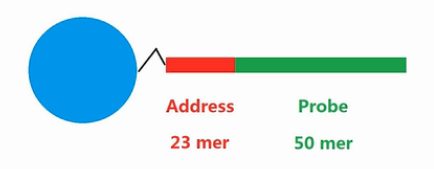
而其中的微珠是实现 SNP 芯片功能的基本单元。每个微珠上都固定了一端 DNA 序列,这段 DNA 序列的长度为 73 bp,分为两个功能区:
- Address 区:地址区,23 bp,是每个的微珠的唯一分子标识。一张芯片上的每个微珠对应一个 Address 序列,每个 Address 对应一个 Probe 序列。
- Probe 区:探针区,50 bp,用于与目标 DNA 进行分子杂交,并进行下一步的单核苷酸扩增。具体工作机制见下一节。
由于 Address 区的长度为 23 bp,容易知道,理论上共可以存在 10 13种不同的 Address 序列,即在一张芯片上,至多可以放置 1013 种不同的 Probe。Illumina 在将芯片出厂前,会对安置的所有微珠的 Address 进行检测,将 Address 和 Probe、微珠坐标一一对应,存储在 .dmap 文件中。只有借助这个文件,才能解读芯片的内容。
2. 分子杂交和单核苷酸扩增
这一部分也就是 Probe 序列的核心功能。
Probe是根据 SNP 位点设计的,具体有两种
- Probe 序列的设计刚好停在 SNP 位点的前一个碱基,也就是说,当样品与 Probe 杂交后,Probe 结合区外的第一个碱基,就是 SNP。这样,Probe 便通过分子杂交固定了 SNP,只要检测出结合区外的第一个碱基,就能知道该微珠的 Probe 对应的 SNP 分型了。
- Probe 序列刚好覆盖 SNP 位点。也就是说,存在 Probe 与目标 DNA 完全互补与 Probe 与目标 DNA 仅最后一个碱基不互补的情况。这样,在不互补时,下面马上提到的单核苷酸扩增便无法进行。
当 Probe 捕获目标 DNA 后,将使用带有标记的 dNTP 进行一个单核苷酸扩增,这将为 SNP 带上荧光标记,最后,通过激光扫描每个微珠的荧光信号,就能完成 SNP 分型了。
然而,Illumina 的荧光标记只用红和绿两种,这如何区分 ATCG 四种碱基呢?解释如下:
A、T 两种碱基是通过 DNP 标记的,在显色后,会产生红色荧光;C、G 两种碱基是通过生物素标记的,在显色后,会产生绿色荧光,那么,对于所有碱基的纯和、杂合情况,根据红色、绿色、混色,无色四种情况便可以对 SNP 进行分型了。